Developing Custom React-Redux Framework — Reducing Developer’s Effort — Part 2
In our previous article we talked about the basics of Redux, its pros/cons, and a gist of how we, the dev team at Codeparva, have created our own custom framework to fix some of the basic redundancy and network middleware issues.
If you are not coming from the previous article, I would recommend you to go through it first. It will give you the idea of what are we discussing here and why we chose this path.
Now, let’s take a look into how we have implemented our custom framework and how it has helped our developers gain better control over Redux, resulting in a faster development cycle.
Configs
The framework is designed and developed in such a way that even those who are not familiar with Redux core concepts should be able to use it with a minimal learning curve. That’s why our framework is config driven. Just like code and data, that should reside in separate entities; we have kept our focus on a config driven approach to keep our logic detached and reusable. Some of the configs that we use in the framework are:
Dependency Config:
This config is used to define dependencies of the component(s). There are two ways, using either of which, you can define the dependencies of a component — on route level and component level.
In route level, we use a route (just like /user/view) as a key and list down all of its dependencies with appropriate priority, on the value side. When a particular route gets hit, all of the dependencies are captured from the store and are sent to the component, which gets mounted on the route defined. If the dependencies are not present in the store they will be fetched and served.
In component level approach, the dependency calculation and fetching remains the same, just the dependency calculation happens every time the component is mounted.
Dependencies can be critical, lazy or onDemand. If the data is critical for component mounting we define the dependency as critical, but, if the component can be mounted without the data we define the dependency as lazy; the component gets mounted and the data is fetched in the background. OnDemand dependencies are fetched on-demand by the component based on user interaction.

Route Level Config

Component Level Config
Action Config:
Action config can also be called as a request-config. Here, we define and store the information required to fetch the data for the store keys. This includes the URL, the payload, the request-methods, etc. The keys used here are the same store keys that have been used in the ‘Dependency config’. The framework uses this config to fetch the data for any store key, and if there is no defined config related to a store-key, no network call is made.

Action config for ‘storeKey1’
How does a React component integrate with this redux framework?
Now that all the required configs are in place we can make our component Smart. We call a component smart when it is wrapped with our custom redux HOC. This HOC has access to connect() and mapStateToProps() provided by the react-redux library.

Defining a smart component
Using the above line you can make your component smart and now the component is ready to request data from the store.
Store Key Status: Every store key is given a status which indicates the state of data. This is very useful when your view-page or the transitions depend on the state of data.
- INVALID
- LOADING
- LOADED
- UPDATING
- UPDATED
- ERROR
Request Type: A request type is used to identify the relation of the network call with the store key. We can use this to initialise, refresh, update, append data or delete a store key. In our use case we needed different types of network calls. Below are listed some of the major request types that we have identified in our use case, and based on these we manipulate the store differently, like whether to re-fetch the store data or not.
- INIT
- REFRESH
- PAGINATE
- UPDATE
- DELETE
Now let’s understand how the overall framework works. When a component gets mounted or a particular route is hit, the framework will first load all the dependencies of the route/component. Based on these dependencies the required data is requested from the store, if the data is not present in the store, then the framework will create a network config and it will make the API call to fetch the data. Also, if the dependency is critical to the component then the framework will wait until the network response before mounting the component.
As mentioned in the above lines, once the dependency is discovered and the network config is created, the framework checks the store data before fetching it outright. If the store key’s data (to be fetched) is already in loading state or is already loaded, then we skip the network call (unless it’s a refresh request type) and directly send the data to the component.
We have introduced a store helper that is used to perform the API call and trigger data post-processing as and when required.
Post processor takes the data from the store helper and processes it. Post processor also handles the error codes in the API response. Custom post processor can always be defined for any of the store keys.
Once the data post-processing or error-handling is done, we dispatch an action based on the store key and request-method. The action creator takes the dispatch action and passes it to the reducer along with the data. Finally, a reducer, based on the action and request-type, filters/splits/appends the data to the store and passes it on to the component as a prop.
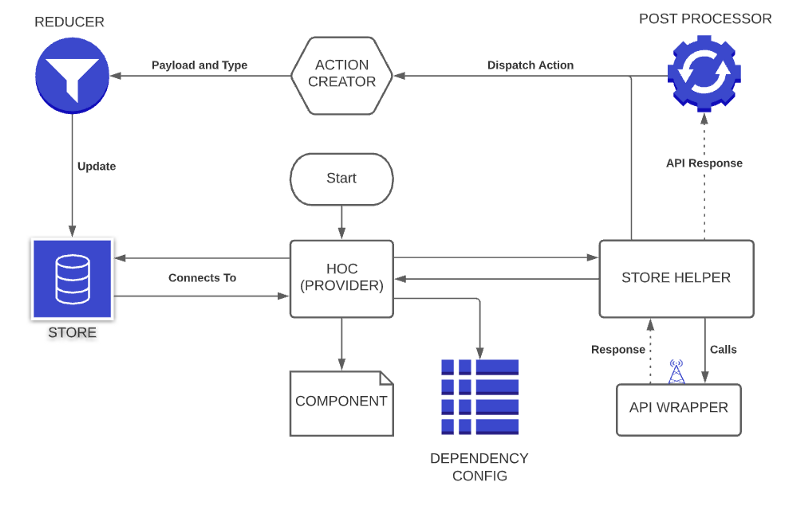
CodeParva’s Custom Redux Wrapper
Additional Responsibilities
For better control, we have pushed some more responsibility to this framework, such as handling permission checks — loading the data only if the user has required permission, handling the error/unauthorized scenarios. It can also load the components in a lazy manner, which further optimizes the performance.
Curtains Closing..
Overall, this custom framework has made our development process very easy, fast, and robust. Not everyone has to worry about the burdens of Redux — like handling and making network calls; the framework handles it implicitly. This has also made the handling of asynchronous requests in Redux way easier and on-demand, the closest we can resemble to is Redux-Saga, but it has its own steep learning curve.
Developing this framework has been a great learning activity, handling all the edge cases, understanding the internals of dispatchers/reducers and to provide generic enough interface for all the use cases.
To learn more about this you can always connect with us. Visit CodeParva Technologies to know more about us.

