Powering up Django ORM with Elasticsearch for Avoiding multiple database calls
INTRODUCTION:
Django has proven to be a powerful web-development tool and is helping boost productivity in writing web applications. It follows the MTV architecture — model, template, and view. View handles the API endpoints, template handles the HTML and model does the database work. Starting with Django is smooth and simple, but when your app starts growing, adding real-world business constraints then the same strategies used in the beginning aren’t that effective and efficient.
Django is a good framework, but not the best in all scenarios. Its ORM offers a great help and simplicity in abstracting database access, but this simplicity can often become a bottleneck or performance pain points.
The Django CRUD
CRUD or create, read, update and delete. These are the most frequent operations performed in any database. Depending on business requirements developers design and index their databases efficiently. Though, database-designing is a very important aspect when dealing with databases, database-access seconds by a very small difference.
Usually, small or mid size applications instead of using a third-party DB service, like AWS-RDS, Azure SQL Database, etc, prefer using their own database setup. This custom DB setup is mostly done on the same machine that has the server or on a different machine in same network, depending on the performance and workloads. Here, the db-access performance becomes important because when the app-server and database are on the same machine or in the same network, then virtually there is no network-call, rather just one process calling another process, which is really faster than any API call. But, if the database is setup in a different network or with a third-party service provider, then for every database operation a network call is required, and with every operation you perform on the DB, the access latency becomes more and more crucial. Hence, it really becomes important to not only design your database schema, but to also design the way in which you interact with the data.
Simple REST APIs may require you just to provide endpoints for CRUD operations on a resource or entity, like a book or person. Functionalities like these can be nicely handled by the Django-ORM. But in real-world user flows doing any kind of operation on DB requires a good a mount of validation or pre-processing. Handling such cases with the Django-ORM is possible but may not be efficient.
Example: Consider a use case where you have provided an API to add new books in a store table. This functionality is only accessible to a user of type manager, and the store has a limit on the number of books from each subject, and every subject has a specific pattern for book-names.
Now, when developing this API to add a new book, before adding you would need to validate the user-type, the book-name pattern and book count. If these data pieces were related you could have leveraged Django’s select_related or prefetch_related to solve it. But since they are not, you’ll have to either make multiple fetch calls OR fire a custom SQL OR use sub-queries (if possible).
This was a relatively simple example, but at CodeParva, we are developing a solution for the huge self-storage industry and having very complex user-flows which require validations and checks ranging from names to long rental histories. Getting all the technically unrelated data just to process one flow would have cost us multiple visits to the database. To solve this problem we have leveraged elasticsearch.

Image credits: towardsdatascience.com
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. — Wikipedia.
Using Elasticsearch we have developed a seamless framework that facilitates us querying huge amounts of data in just one network call. Related or unrelated, it just takes one network call to fetch it all. This has given us a good performance boost against the normal Django-ORM.
How did we do it?
- We created ES indices for every Django model (DB-table) we were interested in, with the required mapping.
- Then, for each of the Django model we created a python class acting as an in-memory data-store (just like redux for ReactJS). This data-store also has information about the relevant queries (in ES syntax) for each of the user flows.
- Now, whenever a user hits our API, we use data-stores to create relevant queries and then pass them on to the python’s elasticsearch package for fetching the data from ES-indices.
- This fetched data is stored in the data-stores and consumed by respective services.
The above mentioned approach has proven to be very effective and beneficial in the READ operations as the ES provides us richer ways to query the data and that too with data ranking, if required.
On the other side of the coin, after every line of code that is updating the database we need to update relevant the record(s) in the ES.
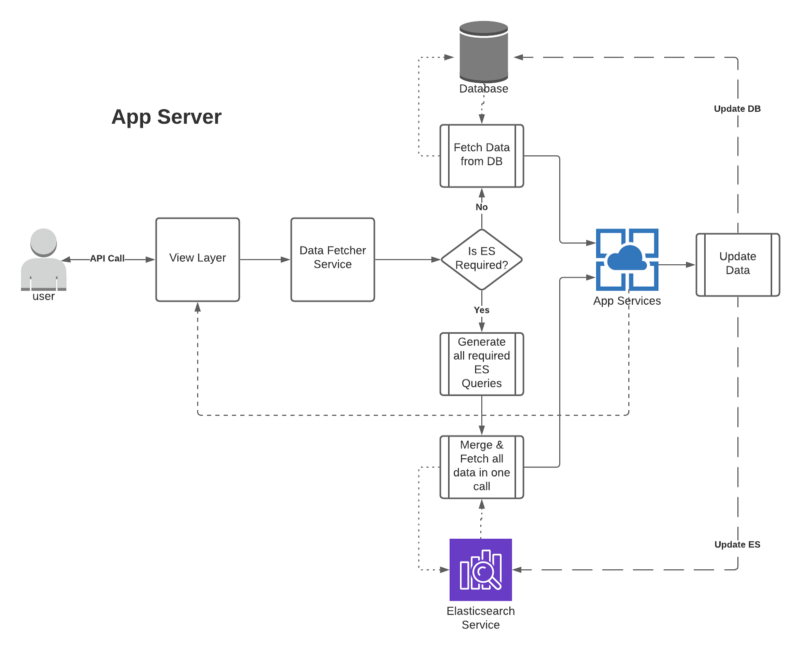
Using Elasticsearch as Data-Store in Django
Elasticsearch has proven to be a great resource for our use case, but it may not be the best choice for everyone, checkout some of its pros and cons listed below.
Elasticsearch Pros:
- Fast & efficient storage
- Powered by Lucene
- Schema Free
- Text-based searches on data
- Good Analytics Support
Elasticsearch Cons:
- Steep learning curve for beginners
- Tricky to setup
- Hard to Debug
- Only JSON is supported
Final Words:
Elasticsearch is fast & powerful. Instead of searching the text directly, it searches an index, that is based on the text. Just like using an index in a book. Retrieving pages related to a keyword by scanning the index, instead of searching every page for the word.
Additional Links:

